技術
![]() 2026.03.18
2026.03.18
![]() うねりの泉編集部
うねりの泉編集部
Vertex AIで実現:購買データ x 約1億IDの人流データによる次世代広告ターゲティング / 「 Google Cloud Next Tokyo 」登壇レポート

「Google Cloud Next Tokyo」はGoogle Cloudが年に1回開催するイベントの日本版で、クラウド技術の最新情報や事例の紹介に加え多彩なワークショップなどを含み、今年は2025年8月5日(火)と6日(水)の2日間、東京ビッグサイトで開催されました。
本記事は8月5日のセッションでunerryの3名が登壇した「Vertex AIで実現:購買データ x 約1億IDの人流データによる次世代広告ターゲティング」を書き起こし風にレポートします。
(実際の発言から編集を加えています)
※人員数やデータ量に関する記載等、本記事に関する内容は2025年8月5日時点での内容となります。
INDEX

皆さん、こんにちは。unerryは、位置情報を中心とした行動ビッグデータを保有する企業です。本日は、Vertex AIを活用して広告ビジネスにおける新たな強みを確立した事例を紹介します。
まず、自己紹介をさせていただきます。私は梅田と申します。unerryでは広告ビジネスの推進を担っており、本取り組みではビジネス側の要件定義とプロジェクト推進を担いました。
後ほど登壇するデータサイエンティストは2名おり、張が機械学習モデルの開発マネジメントを、上野が主に実装を担当しました。本日はこの3名で説明いたします。
アジェンダは、最初に弊社unerryについて、次に次世代広告ターゲティングの概要、最後にVertex AIを用いたMLOpsの活用方法についてお話しします。
会社紹介
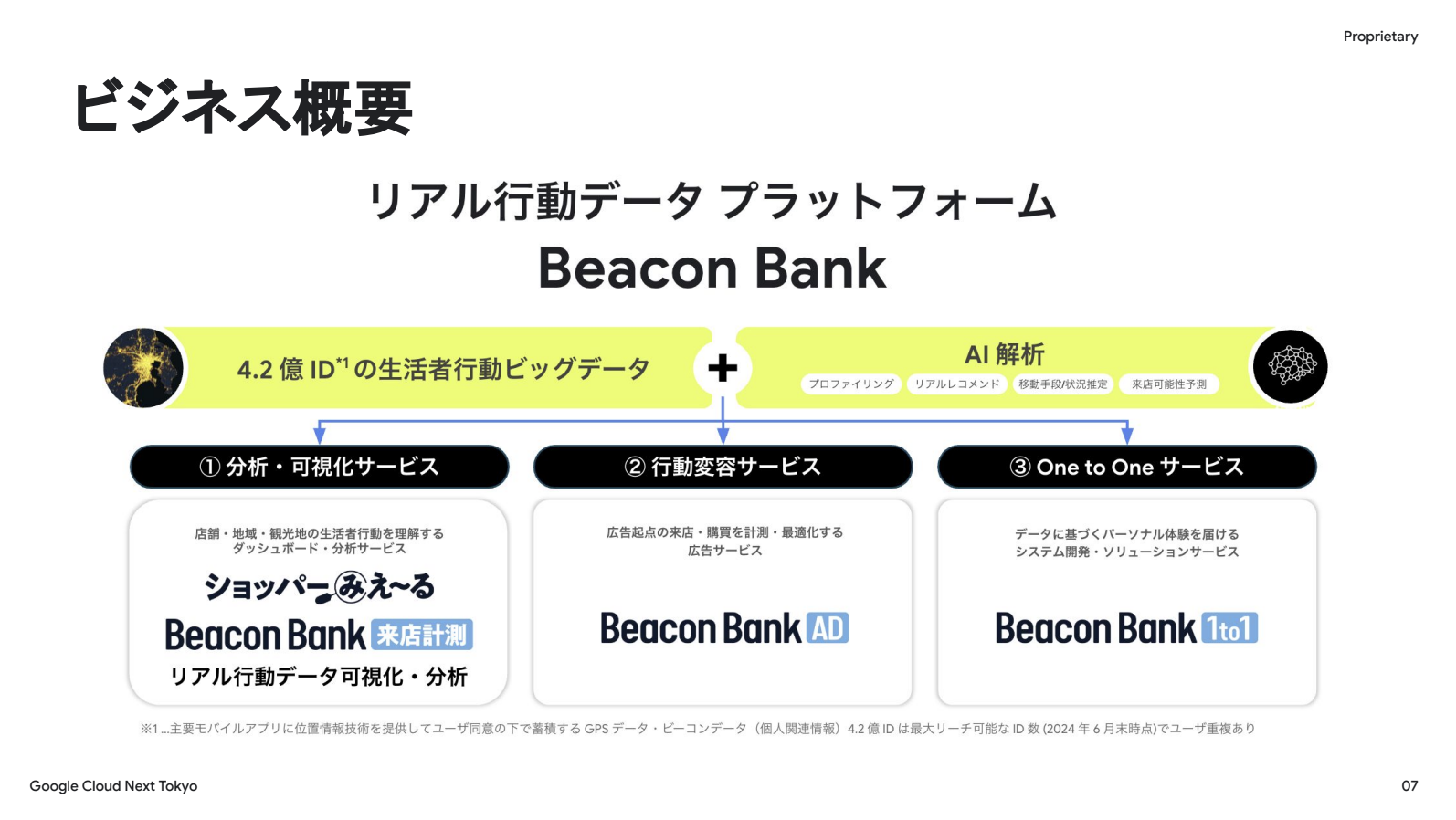
unerryは、リアル行動データプラットフォーム「Beacon Bank」を中心に事業を展開しており、国内外で4.2億IDの生活者行動ビッグデータを保有しています。このデータを解釈するAI技術を活用し、以下の3つのサービスを提供しています。
1. 特定のお店や街への来訪者を分析・可視化するサービス
2. 分析結果に基づき広告を配信し、実際の来店を検証する広告配信の仕組み
3. One to Oneのパーソナライゼーションを行うシステム開発
当社が保有する生活者行動ビッグデータの核は人流ビッグデータです。データソースは主にスマートフォンのGPSデータと小型のビーコンセンサーの2種類です。日本と北米を中心に展開し、グローバルで4.2億IDを保有しています。この人流ビッグデータには、IDで紐づく形で購買データやテレビ視聴データなど、生活者のあらゆる行動データが結びついています。
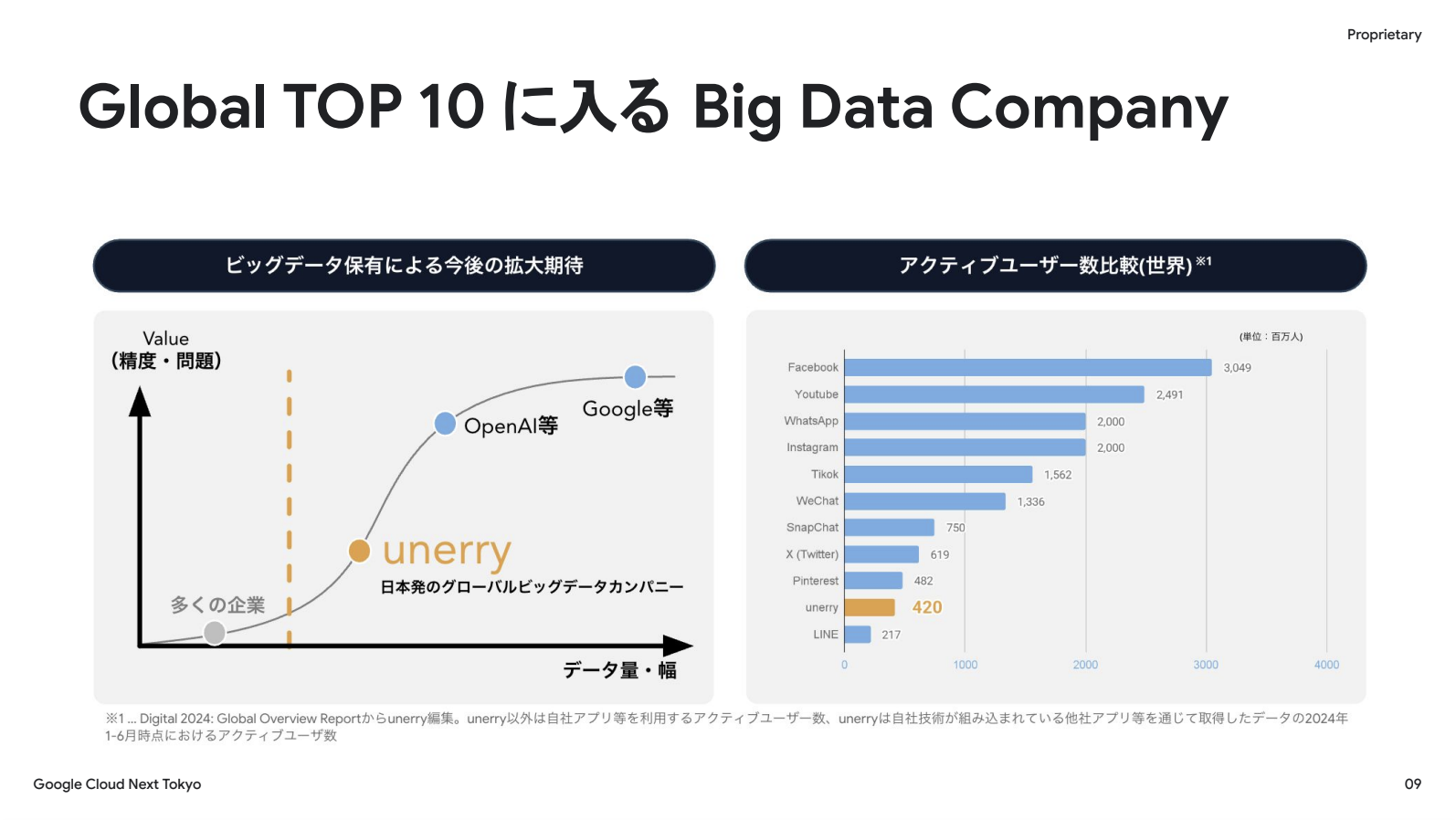
4.2億IDはグローバルでもトップクラスの規模です。unerryは、データ量が一定の閾値を超えるとモデル性能が非線形に向上するデータスケーリング則の域に達しています。世界トップクラスのユーザー数を誇るプレイヤーは、このデータを用いて独自の生成AIモデルやレコメンドシステムを開発しており、unerryも同様のデータボリュームを有しています。
次世代広告ターゲティング
今回は行動変容サービス、すなわち広告領域での事例について説明します。
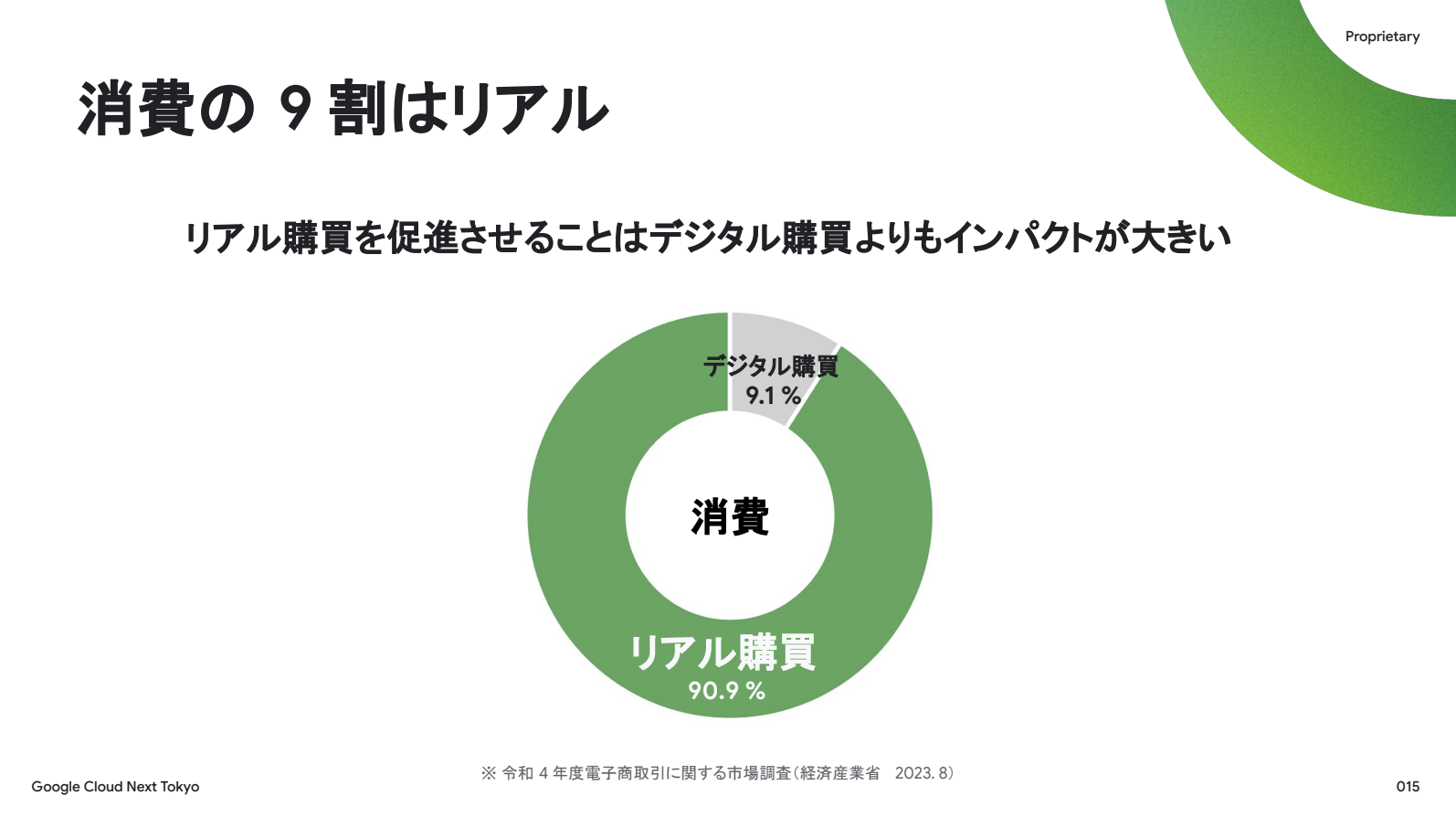
普段のお買い物のうち、リアルなお店、例えばコンビニとかスーパーで買い物する時の支出のどれくらいの割合がリアルで行われるか、ご存じですか?オンラインECサイトの普及により、オンラインでの購買が増加している印象がありますが、実際には9割がリアル店舗で発生しています。もし皆さんがメーカーの販売促進の予算を決める責任者だったとしたら、リアルの施策とオンラインECの施策、どっちに投資しますか?
もちろんインパクトが大きい9割のほう、リアル施策に投資しますよね。

このような背景から、リアル世界をデータ化しているunerryには、近年メーカーからの相談が増加しています。本セッションで紹介する次世代広告ターゲティングは、このようなメーカーのニーズに応えるものです。
次にシナリオを紹介します。広告主であるメーカーは、スーパーやコンビニに陳列される商品を製造し、店頭販促の予算を保有しています。この予算を効率的に活用するため、購買見込み層をターゲットとした広告を検討しています。
この要件に対し、unerryの広告配信サービスでは現在大きく2つのアプローチを提供しています。
1つは、人流データを用いて、例えば商品が陳列されているスーパーを普段利用する層に広告を配信すること。その際に、ジムに通っているなどの行動アフィニティも組み合わせることができます。もう1つは、unerryが提携する企業が保有する購買データを用いた、類似商品を購入している層への広告配信です。例えば、メーカーが新しい健康飲料を発売した場合、unerryのサービスでは、普段から健康食品を購入している層への広告ターゲティングが可能です。
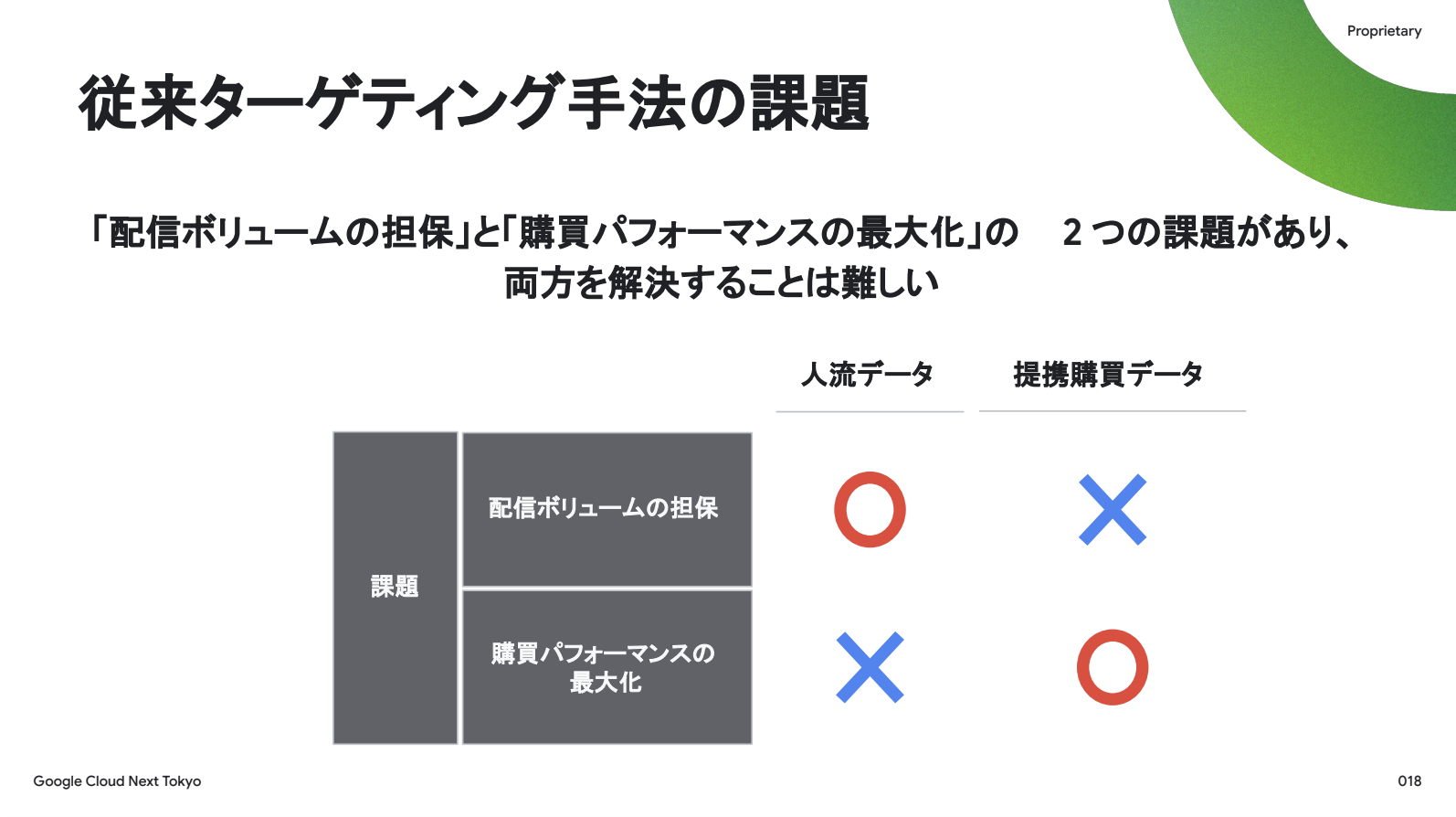
現在提供している人流ターゲットと購買ターゲットの評価について説明します。人流データは国内でMAU約1億規模であるため、配信ボリュームを確保できます。購買データは購買レベルでの消費傾向が把握できるため、予測精度を高く保つことができます。しかし、人流データと購買データをそれぞれ単独で利用する現状では、配信ボリュームの最大化と購買パフォーマンスの最大化という2つの目標を両立することが困難なのが現状です。これは、どちらか一方を優先するともう一方が犠牲になるというトレードオフの関係にあります。
ではどうすればこのトレードオフを乗り越えられるか。人流データが1億IDあるなら、2つのデータソースもそれなりに重なるはずで、組み合わせて活用したら配信ボリュームも「◯」、パフォーマンスも「◯」、という夢のようなターゲティング手法が実現できるのではないかと考えました。

次に次世代広告ターゲティングの全体像について説明します。
日本国内で約1億の人流ビッグデータがあり、ここから独自の2つのプロセスでターゲットを絞り込みます。この2つの絞り込みは僕の体験がベースで、そこから得た教訓から見出しています。
日本昔ばなしと同じように「物語から教訓を得る」という構造でお話しします。
1つ目の絞り込みの元となった体験をご説明します。
あるメーカーさんの新食感のお菓子の広告を何回か見て、だんだん興味を持ち「一度食べてみたいな」と思いました。そこで普段行っているスーパーやコンビニで探したのですが、そのお菓子はまったく置いていませんでした。皆さんも広告を見て「これ欲しいな」と思ってお店に行ったけど置いてなかったことありますよね。結局、僕はいまだにそのお菓子を食べたことがないんです。
この経験から得られる教訓は、効率的な販促のためには、まず「商品を置いているお店に普段から行っている人」にターゲットを絞るべきであるということです。これは人流データを扱うunerryであれば容易に実現できます。
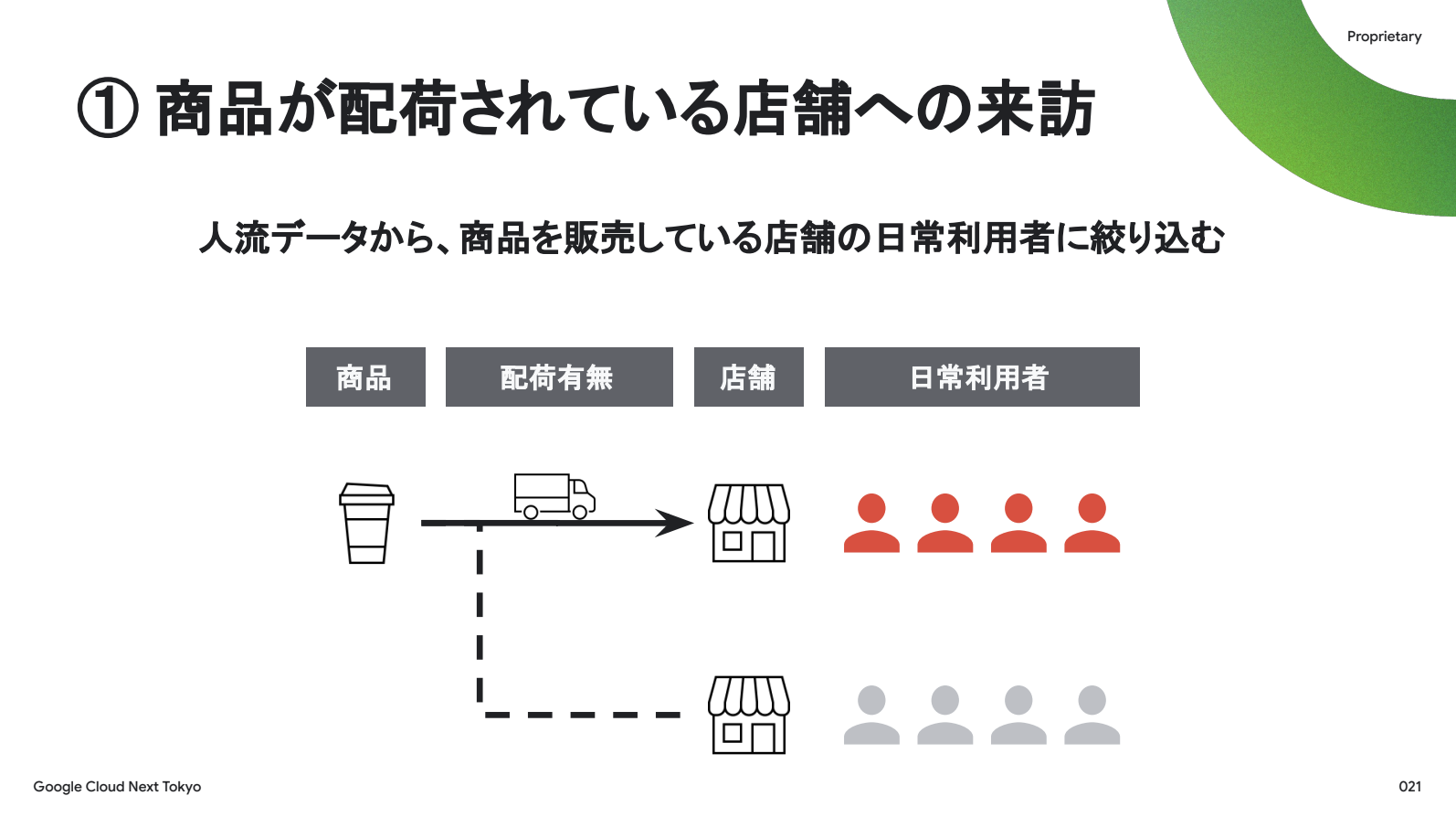
2つ目の絞り込みも体験から。
ある時期、YouTubeでの動画広告やニュースサイト上のディスプレイ広告など、様々なメディアで特定の調味料の広告が頻繁に表示されました。しかし僕は普段まったく料理をしないため、その調味料を購入することはありませんでした。なんならスーパーに行っても調味料の棚にすら行っていないです。スーパーに入ったらお惣菜コーナーに直行し、レジに直行し、家に直行します。料理しないんだから当然ですよね。
皆さんも、興味のない商品の広告が結構出てくる事があると思います。
この経験から得られる教訓は、効率的な販促のためには「商品を購入する可能性が高い人」にターゲットを絞り込むべきであるということです。
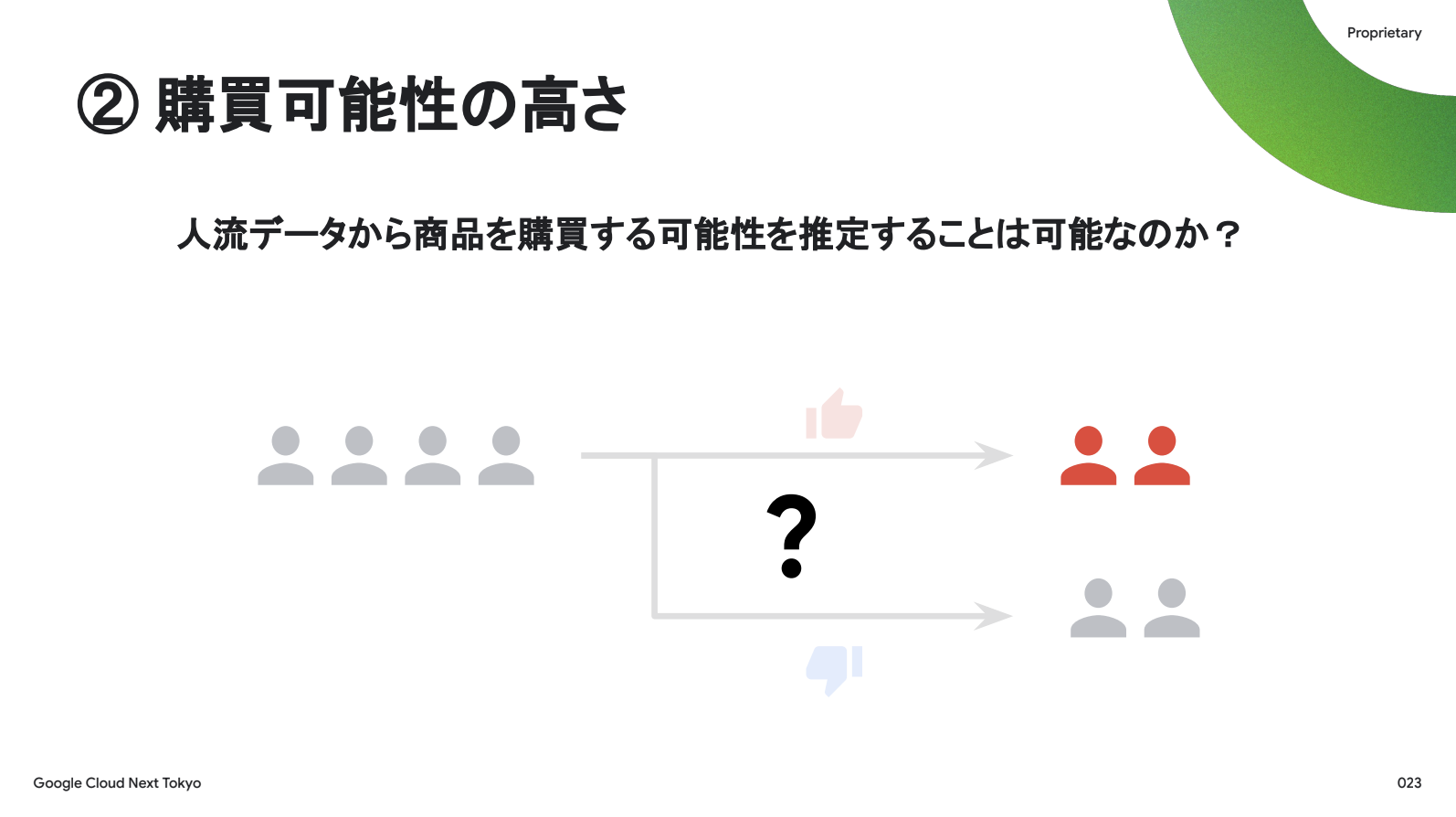
このステップは、先ほどの1つ目と違って、我々は本格的に取り組んだことがない領域でした。ただ、unerryは1億のIDを保有し、そのIDごとに「行動のプロファイリング」、すなわち特徴量を持っているので、何か見いだせるんじゃないかと、ビジネスサイドの人間として夢だけ大きく膨らませました。
この無邪気な夢を、データサイエンティスト2名がGoogleのサービスを使ってスマートに実現してくれました。ここからは、実際にどう筋道を立てて走り切ったかについてお話いただきます。
購買特性と行動特性の関係

こんにちは、データサイエンティストの張です。
さっそくですが、どのようにして人流データから「商品を購入する可能性」を推測するのでしょうか?まずは人流データを多様な外部データと統合し、いろんなユーザーの特徴量を作成します。
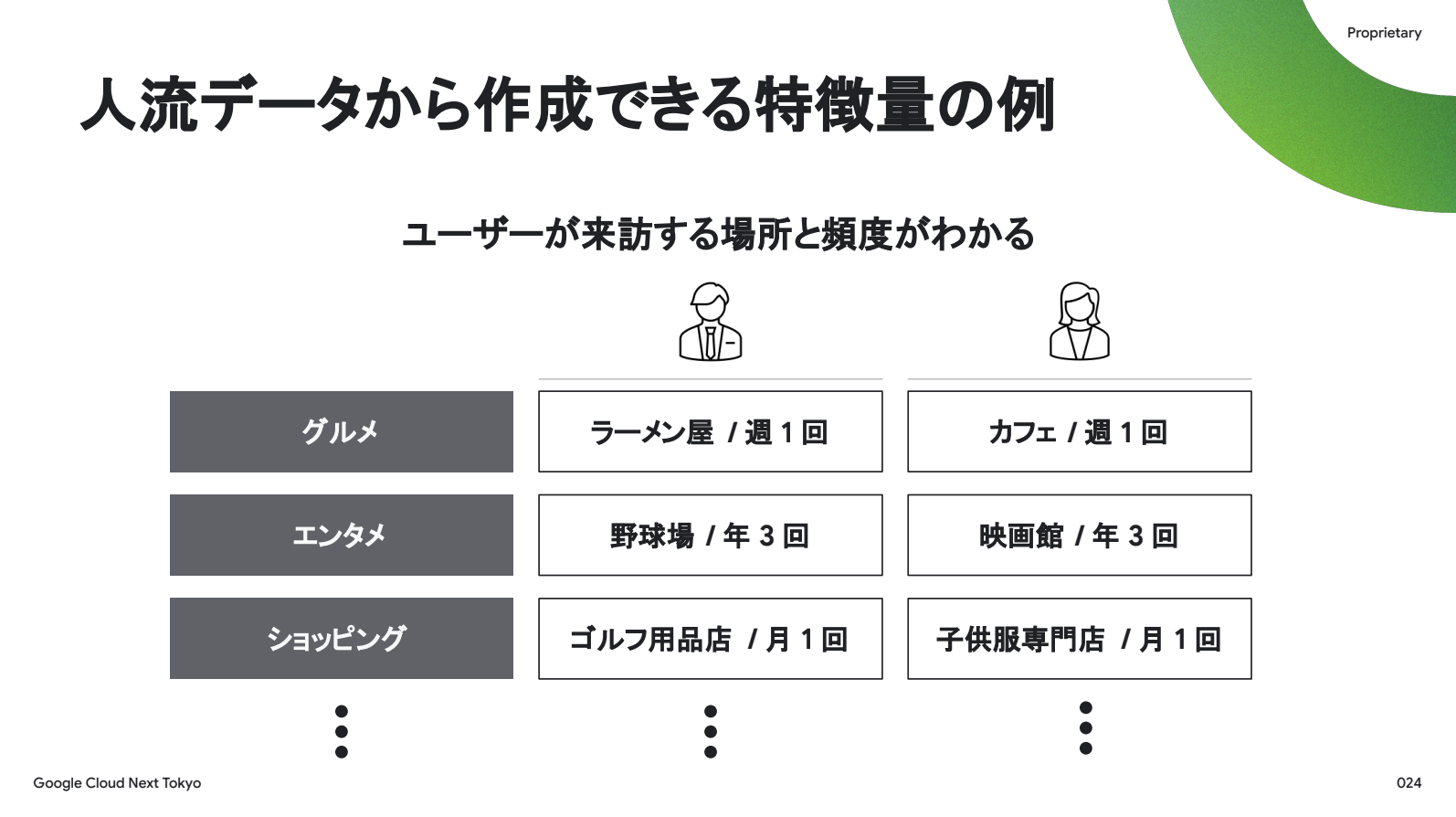
1つの例を挙げると、人流データを日本全国254万箇所以上のPOIデータと掛け合わせて、ユーザーが来訪する場所と頻度という特徴量を作れます。スライドの例のように、この特徴量はユーザーの行動特性を反映できると考えています。

また、先ほどの行動特性は購買特性と関係があるかについて確認しました。
実際の分析の例では、ベビー用品を購入するユーザーは大型商業施設への年間来訪回数が全体平均より30%多く、一方で居酒屋への年間来訪回数が全体平均より25%少ないという結果が得られました。ベビー用品の購入者像を想像すると、非常に腑に落ちる結果ですよね。
人流 X 購買データによる購買予測モデル
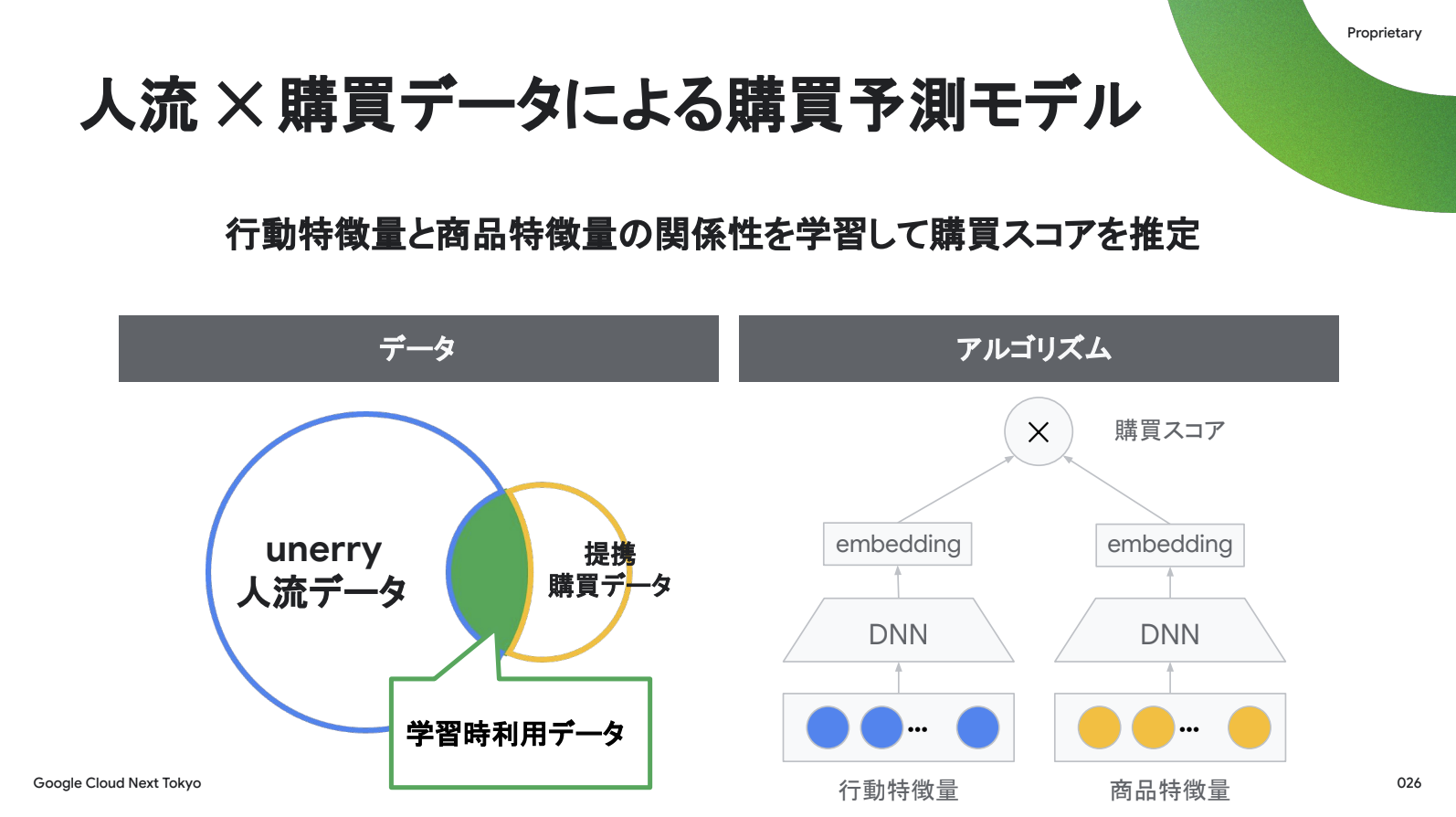
アーキテクチャについては、要件が4つありました。
1つ目は「数億行の大規模データに対して効率よく学習できること」です。このアーキテクチャでは2つのタワーがニューラルネットワークなので、GPUを使えば大規模の並列学習が可能です。
2つ目は「商品の説明文や画像も利用したい」ということです。このモデルでは入力はベクトルになるため、今流行りのLLMを使って画像や説明文などの非構造データもベクトルに変換して取り込むことができます。
3つ目は「新商品に対しても効率よく再学習できること」。我々のデータは大規模なので、新しい商品が追加されたりユーザーの行動情報が変化しても、モデル全体を再学習すると時間がかかりますが、このアーキテクチャでは2つのタワーが独立に学習できるため、一方を更新する際にもう一方を必ずしも更新しなくて良いという構造になっています。
最後の4つ目は「広告対象の商品に対して1億ユーザーに対しても効率よく購買スコアを計算すること」です。ユーザーベクトルを事前に用意すれば、新しい商品のベクトルに対して近傍探索をすれば、例えば1億ユーザーから一番近い200万人のIDを抽出することが簡単にできます。
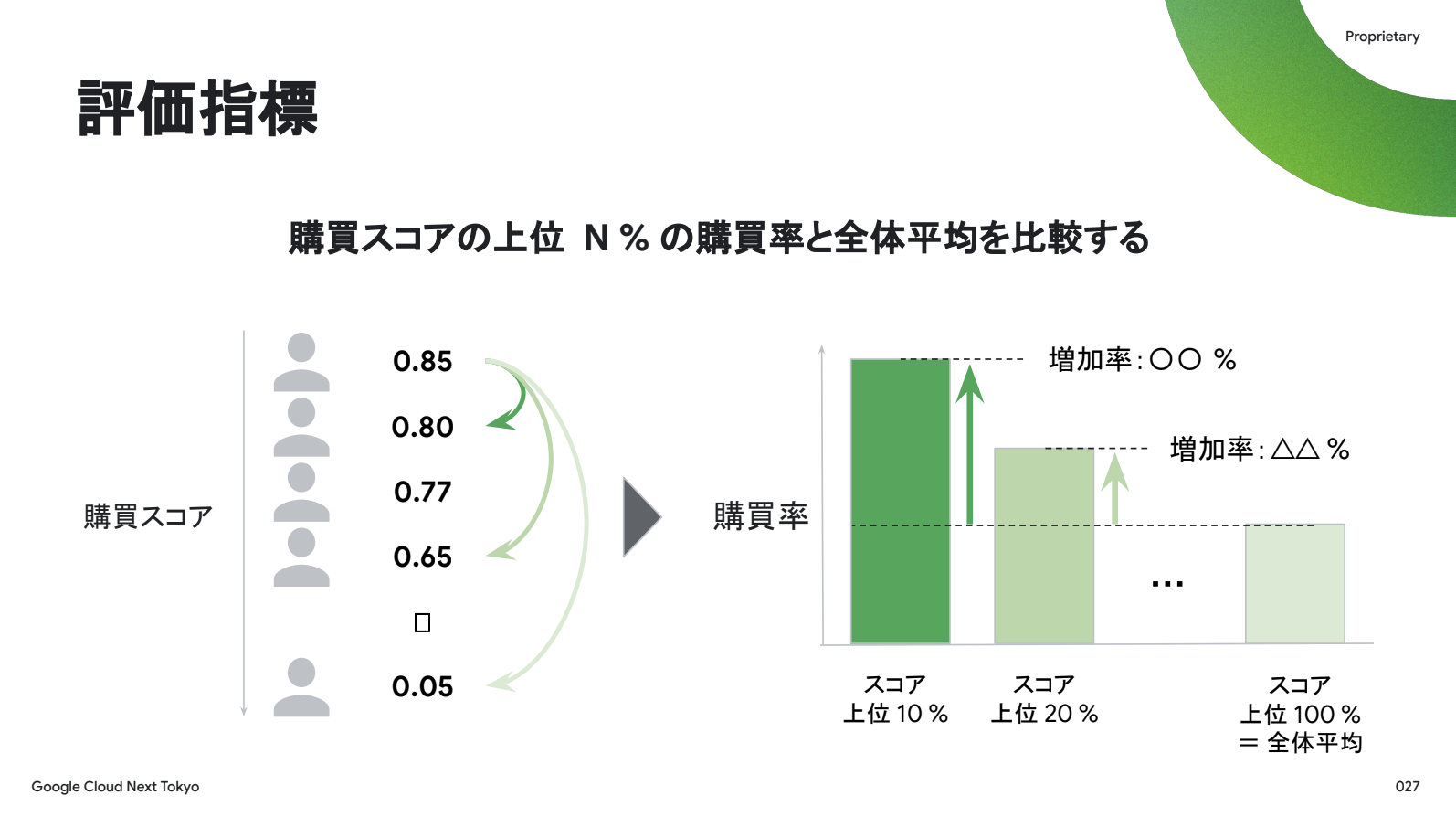
そして構築した購買予測モデルを評価するために、購買スコアの上位N%と全体平均を比較します。ベビー用品の例で説明すると、まずユーザー一人ひとりの購買スコアを推定し、スコアが高い上位10%のユーザーの購買率が全体平均と比べてどれだけ差があるのかを可視化します。
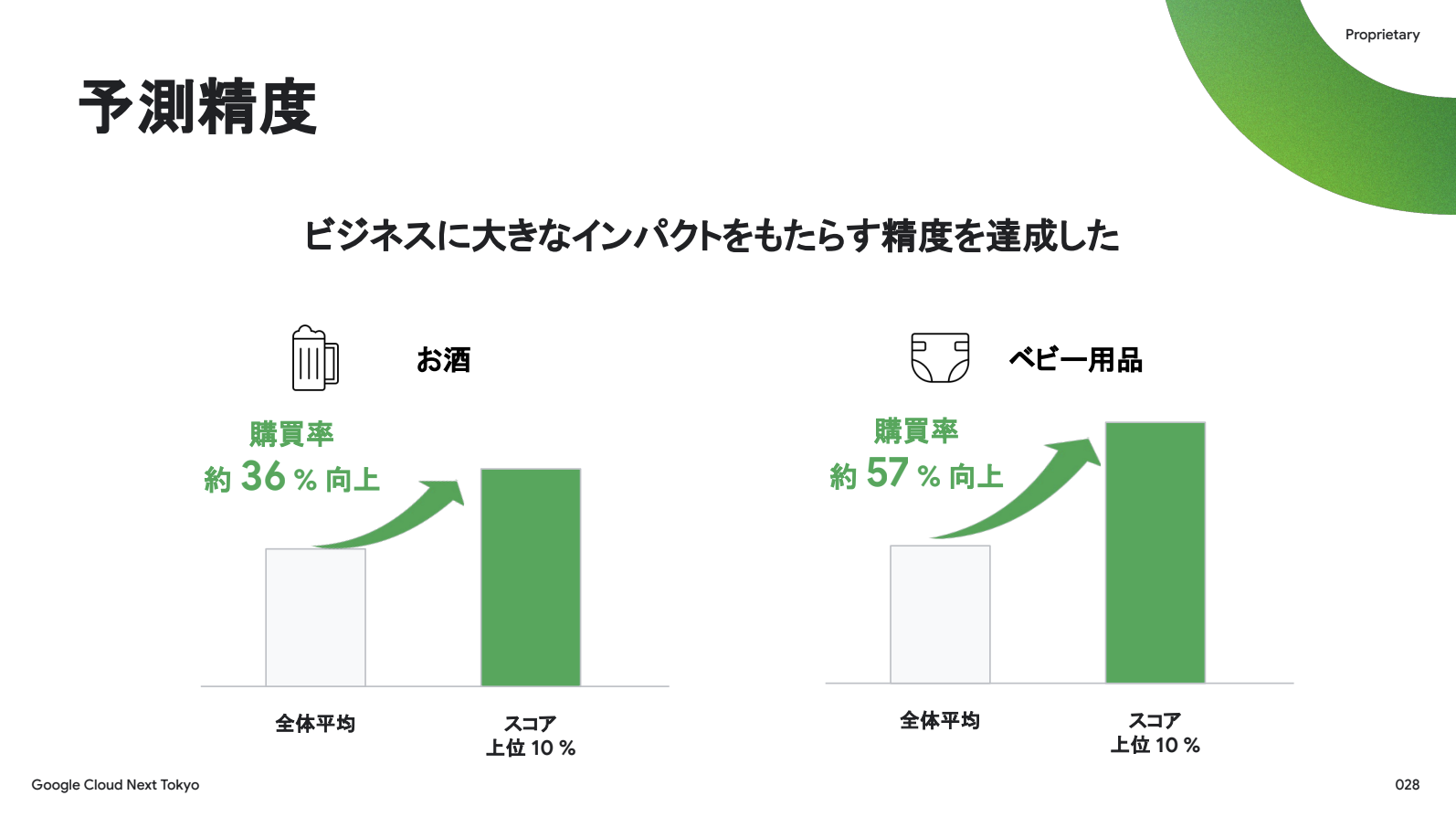
その結果の一部をお見せすると、お酒とベビー用品で上位10%のユーザーはそれぞれ全体平均より36%と57%高いという結果になりました。これは広告予算を購買見込みの高い層への最適配分に非常に価値のある精度を意味しています。
ここから最後のパートでは、モデル構築で直面した課題と、Google Cloudのソリューションを用いた解決手段について、実装を担当した上野から紹介します。

上野です。よろしくお願いします。
先ほどご紹介した購買予測モデルの開発には、非常に多くの試行錯誤がありました。
データサイエンティストの皆様であれば、何度も改良サイクルを重ねてモデルの改善を繰り返すご経験があると思います。そうした改善フェーズにおいて、今回Google CloudのAI開発プラットフォームであるVertex AIが非常に大きな支えとなりました。どう駆使したかを紹介します。
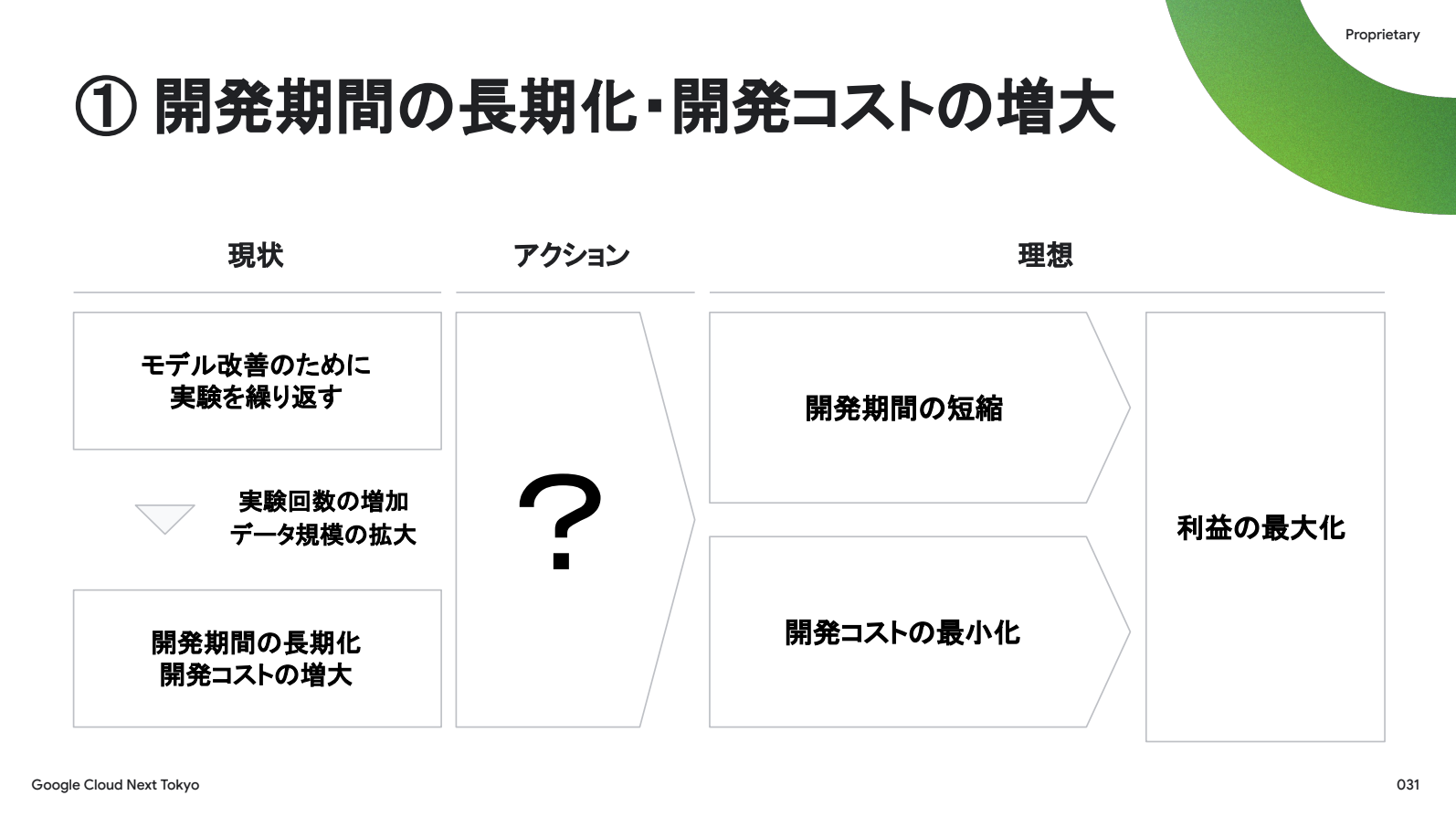
解決した課題は2つあります。
1つ目は開発期間の長期化・開発コストの増大、端的に言うとスピードとコストです。改良サイクルの回数が増えたり扱うデータの規模が大きいことが要因で期間が延び、コストが増大しがちです。ただ、精度を上げるという観点では試行錯誤は不可欠で、データ規模の拡大も受け入れる必要があります。
Vertex AI Pipelinesによる開発期間短縮とコスト削減
そこで登場するのがVertex AI Pipelinesです。
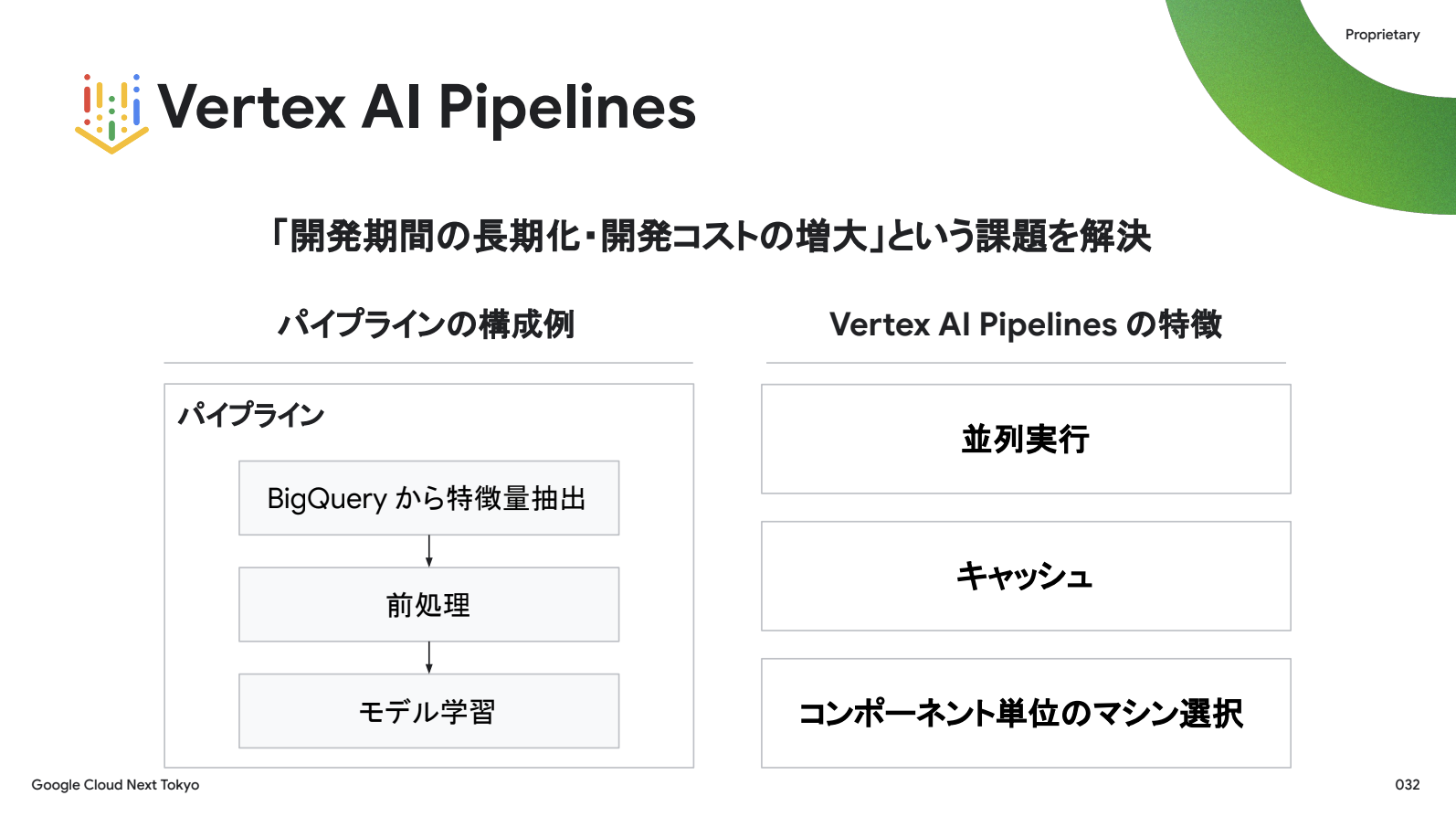
Google Cloud上で機械学習パイプラインを構築・実行するサービスで、例えばBigQueryからデータを取ってきて前処理を行いモデルを学習するといった各ステップを「コンポーネント」として定義します。
なぜ Vertex AI Pipelines が開発期間とコストの課題を解決するのか。これを、並列実行・キャッシュ・コンポーネント単位のマシン選択という3つの観点から説明したいと思います。

並列実行はその名の通りコンポーネントを同時に実行できます。例えばモデル学習を複数のハイパーパラメータ条件で走らせたいとき、Vertex AI Pipelines なら簡単に並列化でき、結果として開発時間の短縮につながります。
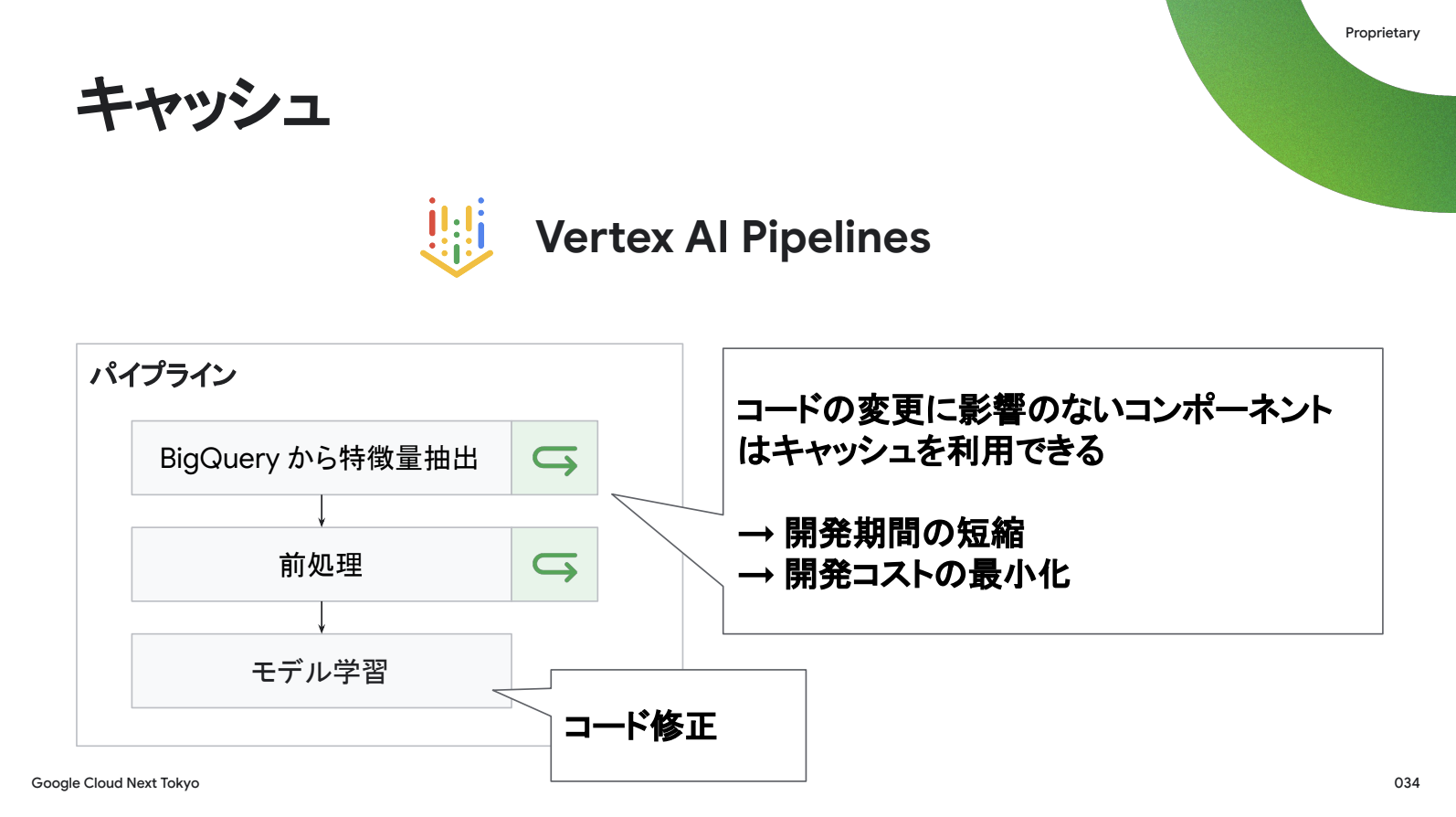
2つ目は「キャッシュ」です。これは一度実行した結果を保存し、2回目以降の実行時は保存結果を参照することで計算を省きます。
例えばモデルのコンポーネントのコードを修正したときに、上流の前処理コンポーネントをわざわざゼロから実行し直す必要はありません。
Vertex AI Pipelines はコードの変更に影響のないコンポーネントに自動でキャッシュを適用し、開発時間の短縮とコストの最小化につながります。
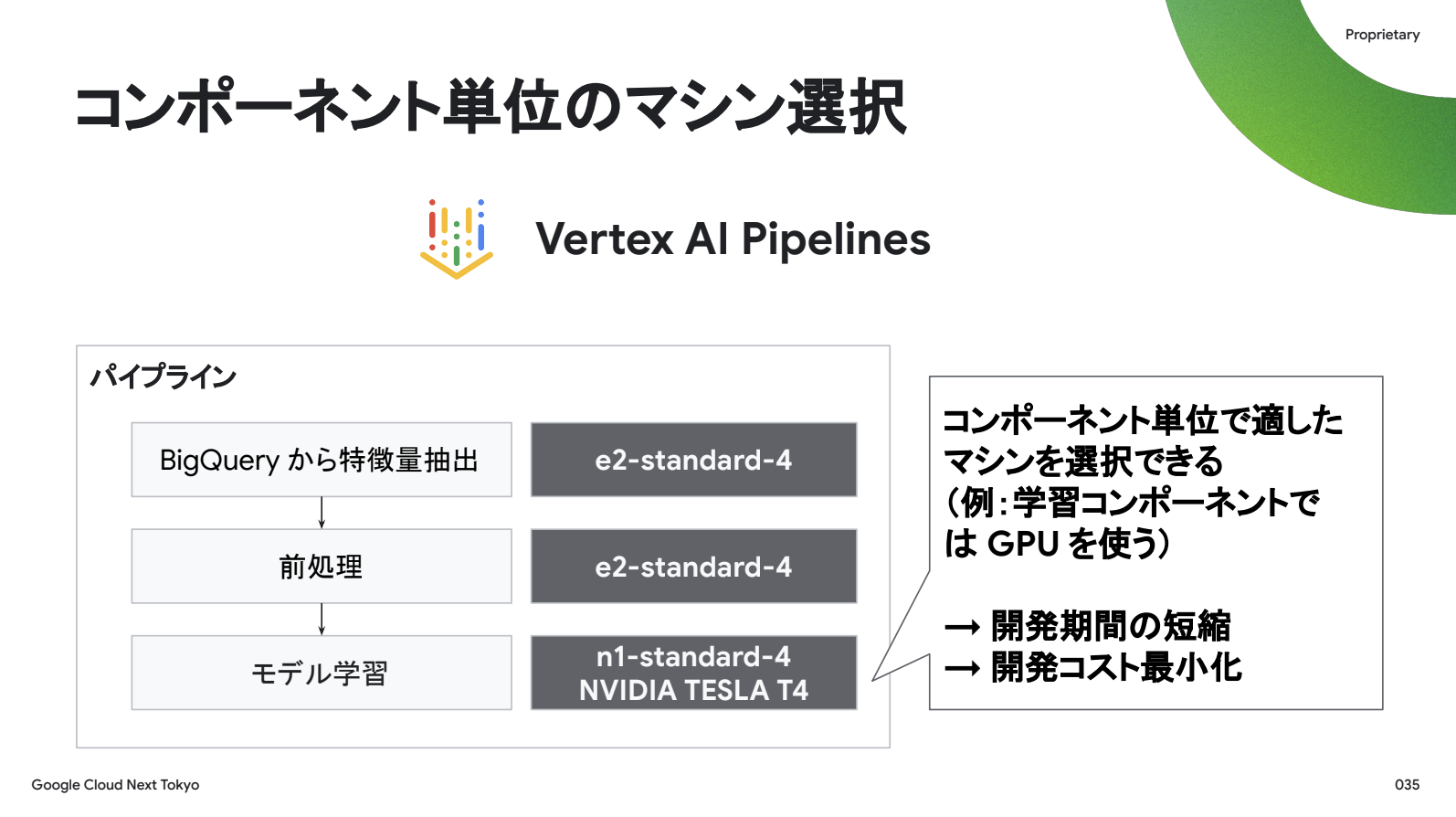
最後の「コンポーネント単位のマシン選択」は、学習だけGPUを使い、前処理は汎用マシンにする、のように各コンポーネントに合ったマシンタイプを割り当てられるということです。結果として、開発期間短縮とコスト最小化を行えます。
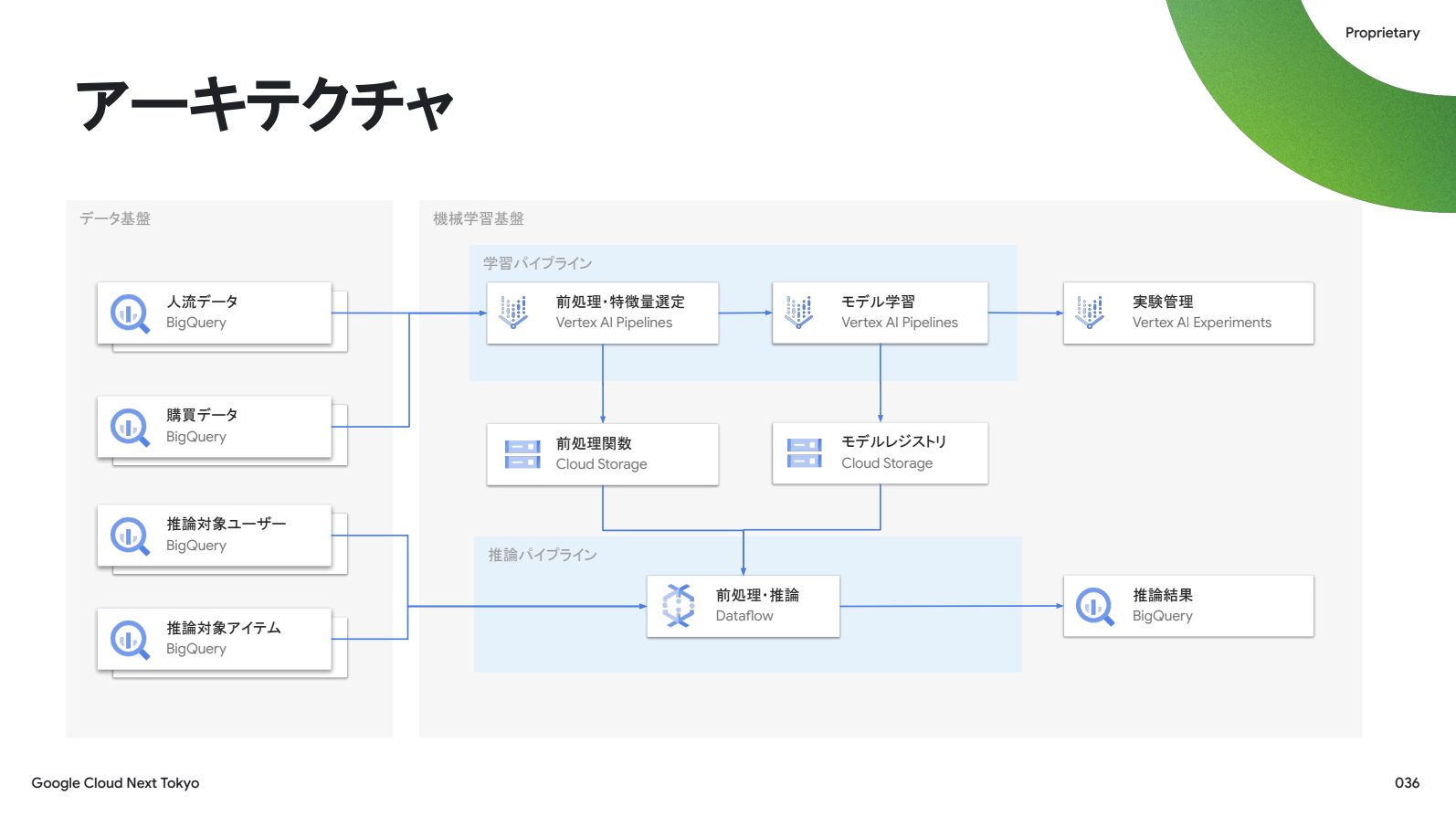
これがアーキテクチャ図です。Vertex AI Pipelines は「機械学習基盤」の中の「学習パイプライン」で活用しています。
Vertex AI Experimentsによる可視化でビジネスサイドとの共創
次に、2つ目の課題はビジネスサイドと開発サイドの壁です。
ビジネスサイドの方をいかに巻き込むかは非常に重要で、ドメイン知識やプロジェクトの目的は改善フェーズでも必要不可欠だからです。実際にビジネスサイドの方にヒアリングすると、1番の理由は「難しそうで意見を言いにくい」。逆に言えば、分かりやすく情報を伝えられれば議論は活性化します。図や言葉などの視覚情報とともに、シンプルに伝えることが重要です。

そこで支えになるのがVertex AI Experimentsです。
実験名やハイパーパラメータ、評価指標を可視化・管理できるだけでなく、“TensorBoard”を用いることで、コード内で定義した評価グラフやモデルの説明(文章)も自動でダッシュボードに反映できます。従来のスライドやノートブックに手で転記する方法と比べて、自動反映という点で作業時間を大幅に削減できますし、管理という観点でも常に自動で最新化されます。
イメージとしては、複数の実験ケースを一元管理し、モデルの説明をMarkdownで分かりやすく記載し、画像タブで実験結果の図も登録できます。ただし可視化はあくまで手段で、目的はビジネスサイドとの共創、その先のモデル改善です。
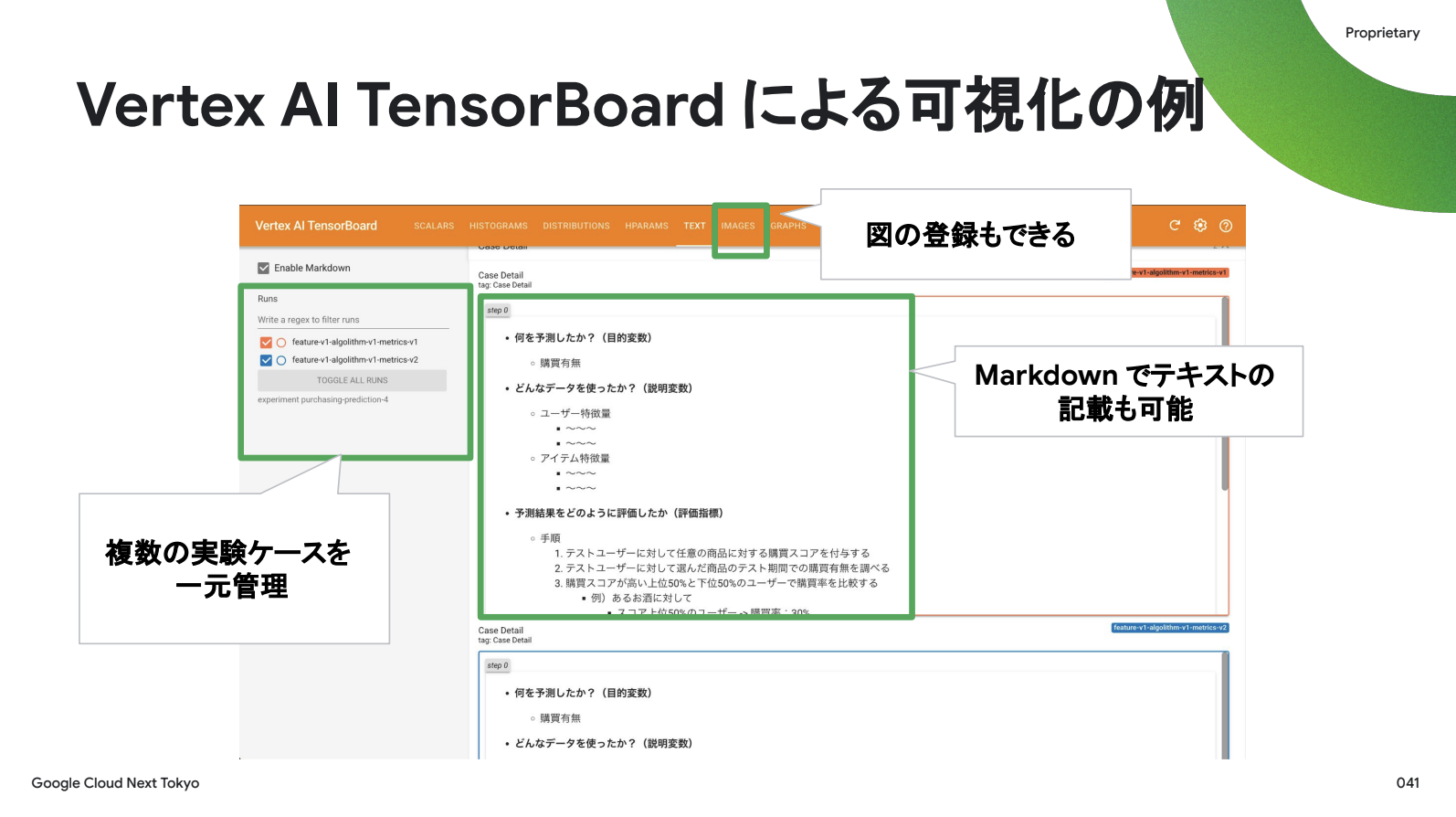
ではこの可視化によってどんな議論が生まれ、どんな改善につながったのか。2つ紹介します。
1つ目は評価指標に関して。はじめは購買スコアの妥当性を評価するのに、スコア上位50%と下位50%の購買率の差を見ていました。しかし「広告配信をした場合の差を想定したい」「現状の案件規模感的には他のレンジでも購買率を見たい」という意見が出て、10%刻みで上位N%の購買率を全体平均と比較できるようにしました。
2つ目は学習方法について。はじめはネガティブサンプリングを行って“買った/買ってない”で学習していたのですが、売上最大化を考えると「どれだけ買ったか」も考慮したい、という議論が生まれました。そこで学習時に購買点数で損失を重み付けして学習したところ、結果的に予測精度が大幅に改善しました。
まとめ

最後にまとめです。主に2つお話ししました。
1つ目は次世代広告ターゲティング、人流データと購買データを掛け合わせることで“ボリュームと精度”という広告ターゲティングの2つの課題解決に挑んだこと。
2つ目はモデル改善フェーズにおけるVertex AIの活用。Vertex AI Pipelinesでコストとスピードを最適化し、Vertex AI Experimentsで実験条件を可視化・管理して議論を活性化し、モデル改善に大きく貢献したことです。
ご清聴ありがとうございました。

最後に宣伝です。unerryは、一緒に働く仲間を募集中です。
膨大な人流データや購買データを扱えて、多く挑戦できる魅力的な環境です。ご興味いただけた方はぜひお話しましょう!
この記事を書いたのは
-

-
うねりの泉編集部 記事一覧
うねりの泉編集部です。unerryのとっておきをお伝えしてまいります。
SHARE THIS ENTRY
-
 0
0
-
 0
0
-
 0
0
-

ABOUT
「うねりの泉」は、「リアル行動データ」活用のTipsやお役立ち情報、そして会社の文化や「ひと」についてなど、unerryの"とっておき"をご紹介するメディアです。


