技術
![]() 2026.03.18
2026.03.18
![]() うねりの泉編集部
うねりの泉編集部
300回超の試行錯誤を経て新卒データサイエンティストが開発に挑む「人流×購買データによる広告ターゲティング手法」

こんにちは、unerry CTOの伊藤です。
2025年9月、データサイエンティスト上野優人が、北海道で開催された「情報科学技術フォーラム(FIT)」において、「位置情報データと購買データを活用した広告セグメントの開発」に関する発表を行いました。

今回の発表は8月の「Google Cloud Next Tokyo」での登壇に続くもので、最先端技術の実装に新卒のエンジニアが挑んだ記録でもあります。
講演内容の核心となる技術、そして若きデータサイエンティストとしての挑戦の舞台裏について、上野に話を聞きました。

登場人物
株式会社unerry テクノロジー&オペレーション部 データサイエンス&AIチーム 上野 優人(うえの ゆうと)

入社日:2025年4月
最近の推し:令和ロマン
筑波大学を卒業後、上智大学大学院 応用データサイエンス学位プログラムを修了。大学院では、「価格・需要変動下における、利益最大化のための販売戦略」に関する研究を行った。在学中より、unerryでの長期インターンを経験し、保有するデータと働く人に魅力を感じて新卒入社。現在は、位置情報・購買データを用いたロジック開発および改善に取り組んでいる。
<聞き手>株式会社unerry CTO 伊藤 清香(いとう さやか)

入社日:2018年2月
最近の推し:ピェンロー鍋
ガラケーからスマホまで20年以上モバイルWebシステムを開発し、高負荷対策をノリと勘で支えた縁の下の力持ち。人生の節目にあたり、これからはIoTで人々の生活を便利にしようと考えて、当時10人位だったunerryへJoin。会社の成長とともに湯水のように湧き出る課題を解決し、働きやすい職場環境を作ることを生きがいとしている。趣味はサッカー観戦と音声制御技術。
第1章:推薦システムを革新する「Two-Tower モデル」の技術的深掘り
伊藤:今回の講演の核となった技術について、詳しく教えてください。
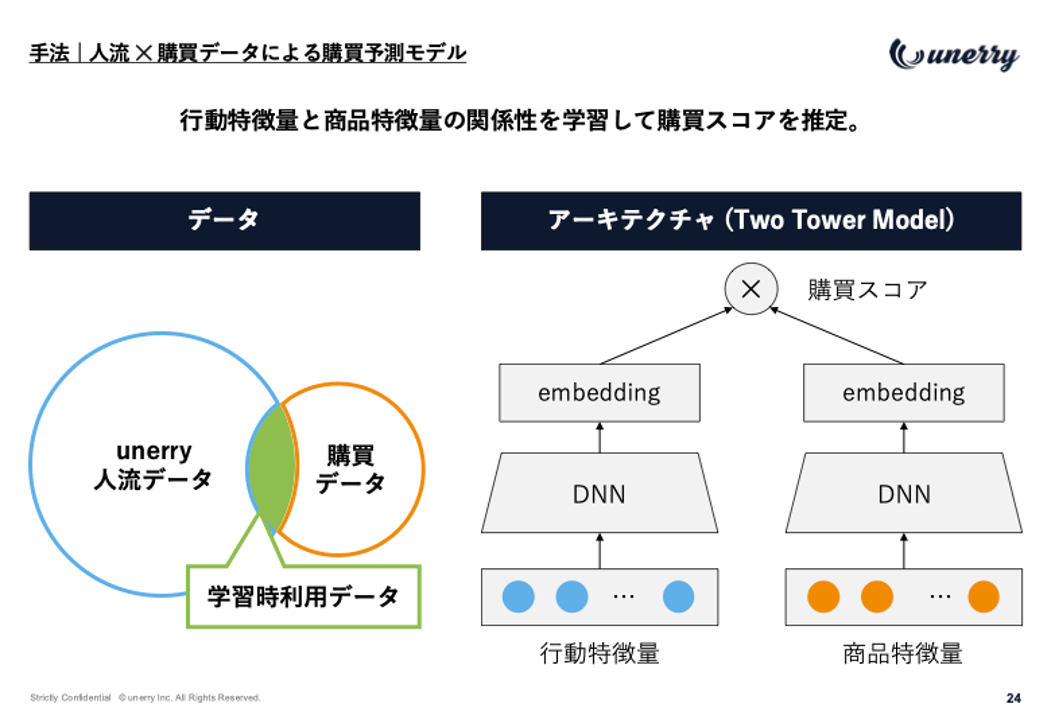
上野:はい、講演では、一言でいうと位置情報データと購買データを掛け合わせた次世代ターゲティングモデルについてお話ししました。このモデルは、ユーザーが過去にどこで行動したかという情報(位置情報データ)を、どの商品を買ったかという情報(購買データ)と組み合わせることで、より高精度な広告セグメントの構築を実現するものです。
この推論モデルは、unerryの梅田と張が共同で発明した特許(番号:特許7641682)を実装したものです。(*1)
そして、その技術的な中核を担っているのが「Two-Towerモデル」というアーキテクチャです。これは、大規模ユーザーに対して高速に推論できるという利点から、YouTubeなど大手テック企業で採用されている先進的なアルゴリズムです。
伊藤:その「Two-Towerモデル」が従来の推薦システムと比較して画期的なのはどのような点でしょうか?
上野:主に、従来のシステムが抱える大きな課題を解決できる2点にあります。
1. 新商品に対する推薦が可能: 一般的に、小売企業が持つPOSデータだけを使った推薦システムでは、新商品を販売する際、購買データが全くないため、誰に推薦したらよいか分かりません。しかし、Two-Tower モデルは、商品の特徴量(価格、カテゴリなど)から生成したベクトルで推薦を行うため、データがない新商品でも適切なユーザーに推薦できます。
2. 購買履歴がないユーザーにも推薦が可能: リテール(小売)の購買データがないユーザー、つまりそのお店で買ったことがないユーザーは、従来のシステムではターゲティングできませんでした。しかし、当社は位置情報データを持っています。位置情報データから抽出・推定したユーザーの行動DNA(unerry独自の指標:普段の行動傾向を示す)や性別・年代といった特徴量があれば、購買履歴がないユーザーに対しても、「この商品を買いそうだ」という可能性を予測できます。
伊藤:その高速な処理を実現するアーキテクチャについて、具体的に解説いただけますか?
上野:Two-Tower モデルは、名前の通り、ユーザーの特徴量と商品の特徴量という2つのタワーで構成されています。
ユーザーの性別や年代といった特徴量、そして商品の価格やカテゴリといった特徴量を、それぞれ深層学習(DNN)で処理することで、意味のある「ベクトル」(埋め込み表現、エンベディング)を生成します。
推薦のスコアは、この「ユーザーベクトル」と「商品ベクトル」の内積 で算出されます。内積が大きいほど、ユーザーがその商品に興味を持っていると判断できます。
高速化の肝は、オフラインとオンラインの処理を分けている点です。
●オフライン処理: 商品のベクトルは頻繁に変わらないため、事前に計算し、データベースに保存しておきます。
●オンライン処理: ユーザーのベクトルだけをリアルタイムで計算し、保存しておいた商品ベクトルと照合(近似最近傍探索)することで、瞬時に推薦結果を出すことができます。
YouTubeなどのテック系企業で採用されているのも、この「大規模ユーザーに対して瞬時に結果を出せる」というスケーラビリティと速度が最大の要因です。ちなみに、今回採用したベクトルの次元数は128次元で、一般的なシステムで使われる700次元や1000次元と比較しても、軽量でリーズナブルな計算資源で済むという利点もあります。
第2章:実装を阻む壁と300回超のトライ&エラー
伊藤:この最先端の技術を実装する過程で、特に大変だったのはどのようなことでしょうか?
上野:非常に多岐にわたりましたが、最大の困難は「実装の難しさ」でした。Two-Tower モデルは概念はシンプルですが、適切なベクトルを生成するための深層学習レイヤーの学習が非常にデリケートで難しいと言われています。実際に手を動かすと、なかなか期待通りの精度が出ませんでした。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
<補足>
Two-Towerモデルについて:
Google の YouTube 推薦アルゴリズムなど、大手テック企業で採用されており、大規模ユーザーに対して高速に推論できるという点で革新的。ただし扱いが難しくまだ広く浸透していない。
参考動画
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
私のログを確認したところ、モデルの試行回数は300回以上に及びました。最初はもちろん、コードの書き間違い(コーディングミス)も多くありましたが、その後は主に「ベクトルの精度をどう上げるか」という試行錯誤の連続でした。
伊藤:ベクトルの精度向上は、具体的にどのように進めたのでしょうか?
上野:精度を上げるためには、モデルに「正解」を教えて学習させる必要があります。私たちは、ユーザーIDに位置情報データの行動パターンから推定した属性を特徴量(性別、年代など)とし、実際の「購買データ」と紐づけました。「このユーザーがこの商品を買った」というデータには「1」(正解)を、「買ってない」というデータには「0」(不正解)を与えます。
そして、モデルが算出した内積スコアが、この正解(1か0)に近づくように、深層学習レイヤーを学習させていくんです。適当なベクトルだと意味のないスコアが出てしまうので、「ここは1ですよ」という正解を与えることで、ベクトルの精度を上げていきました。
伊藤:講演の登壇準備と、このモデル開発を同時並行で進めるのは、相当な負荷だったと想像します。
上野:おっしゃる通りです。登壇の締め切りに追われる中で、コードを大量に書き、試行錯誤を繰り返す日々でした。しかし、その結果として、YouTube や他のビッグテック企業が採用しているのと「同じレベルの技術」を、当社のビジネスに組み込むことができたのは、大きな達成感でした。まさに「困難を乗り越えたからこそ、価値がある」と実感しています。
第3章:学会の独特な雰囲気と、2度の国際的な登壇経験
伊藤:会場の雰囲気はいかがでしたか?
上野:学会の雰囲気は、一般の技術カンファレンスとは異なり、独特の緊張感がありました。リアル会場には20名程度の参加者がいたかと思います。
伊藤:質問はありましたか?
上野:はい、お一人の方から質問をいただきました。登壇内容というよりは、当社の事業領域である「人事領域のAI活用」に関する相談でした。これは、技術広報と採用という今回の登壇目的にも合致しており、意義のある交流となりました。
伊藤:実は、このFITを含めて、上野さんは短期間で連続して登壇されていると聞きました。
上野: はい、プライベートも含めると5ヶ月で4回となります。
① 5月:日本経営工学会(国内学会)
卒業後に参加。大学院での研究テーマ(中古スマートフォンの販売先最適化)を発表。
② 7月:ICPR(国際会議、コロンビア)
指導教員の計らいで、単身コロンビアへ渡航。経営工学に関する研究を発表しました。治安や言語の面で非常にタフな環境でしたが、貴重な経験でした。
③ 8月:Google Cloud Next Tokyo(国内)クラウド技術大規模カンファレンス
④ 9月:FIT(今回の登壇)
伊藤:コロンビアでの単身登壇は驚きです。短い準備期間での挑戦も大変だったと思いますが、何かエピソードはありますか?
上野: FIT登壇の準備期間は1週間ほどしかありませんでした。特に大変だったエピソードとして、飛行機の機内で発表練習をしていたことがあります。
飛行機が遅延し、時間ができたため、PDF資料を読み込みながら、頭の中でプレゼンを再生し、タイマーで時間を計るというスタイルで練習を続けていました。ブツブツと声に出すことはしませんでしたが、頭の中ではひたすら時間を調整していました。
また、登壇全体を通して、先輩から非常に手厚いフィードバックをいただきました。
●「短い言葉で言い切ること」
●「初見の専門用語をいきなり使ってしまうと、聴衆がついていけなくなる」
といった、スライド作成術から話し方まで、実戦を通じて学ぶことができました。特にGoogle Cloud Nextの際は、他の登壇者との兼ね合いで持ち時間が短くなるという裏事情もありましたが、学んだ技術を活かし、説明の核を外さずにコンパクトにまとめることができたと思います。

第4章:未来の仲間へ。「交流」の場としての学会の価値
伊藤:学会全体を通して、上野さんが最も重要だと感じたことは何でしょうか。
上野:それはやはり「交流」です。
発表者側としては、質問を1人からしか得られなかった反省から、いかに相手に興味を持ってもらえる発表をするかという難しさを痛感しました。一方で、聴衆側として、自社のビジネスに関連のあるセッションには積極的に質問しに行きました。例えば、自然災害時に避難場所を教えるチャットボットに関する研究は、当社のビジネスとも関連しそうで、非常に興味深く、質問を通して発表者の方と有益な関わりを持つことができました。
学会は、最新の技術動向を知るだけでなく、普段関わることのない研究者や学生とコネクションを作り、自分では気づかなかった新しい観点での気づきを得られる場です。
伊藤:最後に、同じようにデータサイエンスを深く突き詰めたい学生、そして未来の仲間たちにメッセージをお願いします。
上野:私は大学院で数理最適化を学び、その専門性が現在のデータサイエンスの仕事にダイレクトに活きています。入社後わずか数ヶ月で、世界的にも先進的な技術であるTwo-Tower モデルの実装に挑戦し、それをビジネスに組み込むという経験ができました。
「学んできたことを、社会の現場で直線的に活かしたい」、「困難な技術に果敢に挑戦し、その成果を世の中に羽ばたかせたい」という熱意を持った方にとって、unerryは非常に恵まれた環境です。
私たちと共に、最先端のデータサイエンスを深掘りし、世の中を動かす技術を生み出していく仲間になりませんか?
*1
Google Cloud Next Tokyo ‘25の登壇記事もありますので参照ください。

この記事を書いたのは
-

-
うねりの泉編集部 記事一覧
うねりの泉編集部です。unerryのとっておきをお伝えしてまいります。
SHARE THIS ENTRY
-
 0
0
-
 0
0
-
 0
0
-

ABOUT
「うねりの泉」は、「リアル行動データ」活用のTipsやお役立ち情報、そして会社の文化や「ひと」についてなど、unerryの"とっておき"をご紹介するメディアです。


